

What's happening with DeepSeek?
What's wrong with Nvidia? What's DeepSeek's Deep Secret? Karma anyone?

I. What’s wrong with Nvidia?
Not much. I rate Jensen Huang very highly for his leadership, honesty, and integrity. I recall vividly how he would meet with us (Gartner analysts – I retired from Gartner in the summer of 2018) and ask us to tell him what we thought he could do to improve his enterprise business. We’d have an open discussion – no B.S., little hype.
It’s amazing how different that was (and is) from talking with many other CEOs in the industry.)
According to Bloomberg (1/27/2025), of the ten biggest single-day market cap losses ever, Nvidia had 8 of the 10. To have 8 of the biggest down days in market history, Nvidia has proven it can also rebound.
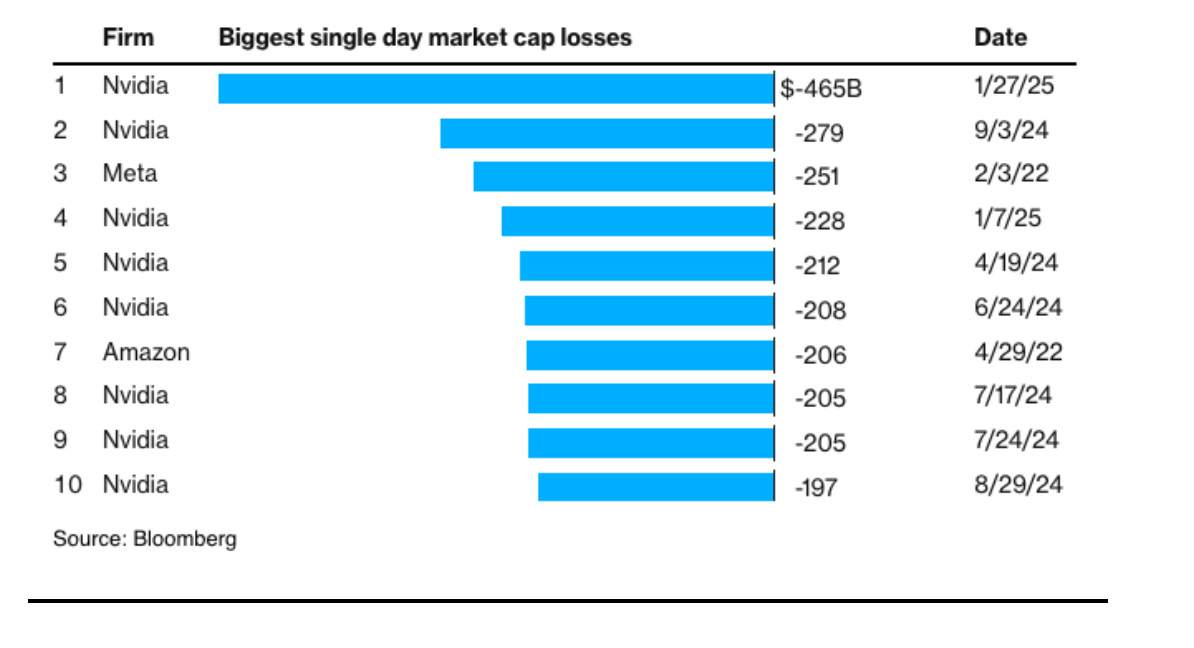
The markets have been quite skitterish about Nvidia in the last year!
At anything close to current valuation, the market will remain skitterish but Nvidia could also climb some more. DeepSeek-R1’s January landing could result in more Nvidia growth than previously anticipated. And the Stargate Project initiative announced in January by executives from Softbank, OpenAI, and Oracle (and Donald Trump) might further boost Nvidia’s business.
II. What is DeepSeek’s deep secret?
Three things stand out:
· Innovation before scaling
· Hiring people who didn’t know the conventional technical wisdom
· Open Source
A. Innovation before scaling. The AI scaling hypothesis is driving the biggest US AI players to focus on scaling their LLMs and related technologies to larger and larger systems, the theory being the only limit on hitting AGI (Artificial General Intelligence) has been the size of their models. Scaling includes using more data, more computing power, and larger models.
DeepSeek seems to have succeeded working in a more constrained environment (number of Nvidia chips), focusing on improving the core algorithms rather than scaling up first. “Nail it” before you “Scale it” to abuse a metaphor. See We Are Just Scaling AI And Not Coming With Novel Ideas.
B. According to various sources, DeepSeek also sought out the least experienced AI scientists to work on their projects, going for people who weren’t steeped in the conventional technical wisdom and forcing them to invent new ways of working. Meanwhile, the biggest players, particularly stateside (e.g., OpenAI, Anthropic and Google) focused on rapidly increasing scale.
C. Finally, Open Source has been a key part of DeepSeek’s technology sourcing, distribution, and licensing. DeepSeek is based in part on Meta’s OpenSourced llama technology (lowering the cost of developing DeepSeek technology) and DeepSeek’s technology is offered under the MIT Open Source License. DeepSeek’s technology is distributed on GitHub. There are now scores of independent implementations of DeepSeek-R1 based on that licensing scheme.
There are some papers that argue that DeepSeek has misstated its development cost – for example, see the posting from Dario Amodei, Anthropic’s CEO) but the deeper issue is who can make money in the AI business today, where, in my thinking, firms like OpenAI are only hoping to make money after they hit “AGI” (Artificial General Intelligence — AI that is smarter than almost all humans at almost all things, something I doubt we’ll see this decade.)
III. Karma?
Several sources also assert or opine that “DeepSeek may have improperly harvested its data.” This is the distillation argument from OpenAI among other, among others, claiming that DeepSeek may have broken OpenAI’s Terms of Service by “distilling” their intellectual property without permission.
OpenAI says it has evidence DeepSeek used its model to train R1.
The company had noted instances of “distillation” and suspects Chinese firm DeepSeek was behind it. Distillation refers to a technique wherein developers use outputs from a larger, more capable model to obtain better performance on smaller models and specific tasks. While it’s a common practice in the industry, doing so to build rival models violates OpenAI’s terms of service. OpenAI and Microsoft investigated and blocked API access to accounts on suspicion of distillation last year, which they believed belonged to DeepSeek. You can read more in the Financial Times (per Fortune, 30 January 2025, Eye on AI column.)
The New York Times said:
“Distillation is often used to train new systems. If a company takes data from proprietary technology, the practice may be legally problematic. But it is often allowed by open source technologies.
OpenAI is now facing more than a dozen lawsuits accusing it of illegally using copyrighted internet data to train its systems. This includes a lawsuit brought by The New York Times against OpenAI and its partner Microsoft.
The suit contends that millions of articles published by The Times were used to train automated chatbots that now compete with the news outlet as a source of reliable information. Both OpenAI and Microsoft deny the claims.
A Times report also showed that OpenAI has used speech recognition technology to transcribe the audio from YouTube videos, yielding new conversational text that would make an A.I. system smarter. Some OpenAI employees discussed how such a move might go against YouTube’s rules, three people with knowledge of the conversations said.
An OpenAI team, including the company’s president, Greg Brockman, transcribed more than one million hours of YouTube videos, the people said. The texts were then fed into a system called GPT-4, which was widely considered one of the world’s most powerful A.I. models and was the basis of the latest version of the ChatGPT chatbot.
I’m not going to try to resolve this issue!
What impact do you see DeepSeek having in your industry? firm? community?
HI Tom - Interesting blog, but I take exception to one key point you make. You talk about "nail it" before you "scale it". There is kind of an underlying assumption that whatever you nail will be able to scale. Scalability fails when a system runs out of resources, but that does not mean you can just throw resources at a system to get unlimited scale. There are LOTS of places where more resources won't help scaling at all. (See my blog on this here (https://g4as.substack.com/p/why-is-deepseek-so-cheap)). This doesn't mean you can't 'nail it' without considering eventual scaling. The system may never get to that point of resource constraint. But keep in mind the more valuable the results produced, the more likely high levels of scaling may be required. And for this, you may have to go back and reimplement everything - you know, all the work you skipped the first time through. It's an inherent risk you take if you do not plan for scaling at the outset.
One prime example of this is in your data design. Access may not be a problem at lower levels of scale, but can cripple your system as you scale.
Like I said, it may be OK to skip the scaling considerations, but when you hit that wall, it hurts.